
 发布内容
发布内容













Autodesk开源:AI生成CAD的2B小模型完胜GPT5.2
Autodesk Research上周在arXiv上挂了一篇论文,标题叫Zero to CAD。
低调到不像Autodesk的风格。但很多人这两天都在转。

原因是论文里有一组数字,乍看不太对劲。
一个20亿(2B)参数的AI模型,能跑在你手机上的那种,让它从图像生成CAD代码这道题上做到82.1%的成功率。
同一道题,GPT-5.2开到最高推理强度,只有72.2%。
不微调的同款基础模型只有6.6%。
更反常识的是这个2B小模型从头到尾没看过一份真实CAD数据。
它学会的所有东西,都是另一个大模型在反复试错里写出来的合成程序。
Autodesk这一手,本质上是把困住AI画CAD这件事好几年的数据墙,用一种很取巧的方式绕了过去。
对3D打印行业来说,这意味着AI生成可编辑模型源文件这件事,第一次有了像样的路径。

3D打印行业一直在等的那种AI
打印机这两年迭代得很快。
多色、高速、大尺寸、多材料,新机型一年能发好几代。
但有一件事没怎么动,可编辑的模型源文件从哪里来。
不管是工业用户做小批量定制件,还是消费用户打游戏手办,模型来源就那么几条路。
自己画,找设计师外包,从模型站下载现成模型,或者拿照片用网格扫描重建。
除了前两条,出来的是都是死网格。
死网格的意思是,你能打印它,但你不能改。
想把孔位往左挪两毫米,想把壁厚加一圈,想把卡扣的间隙调小一点,对不起,从头来。
整个行业都在等一种AI:
你给它一句话或者几张图,它给你一个能改、能调、能直接进切片的真正CAD源文件。
不是网格,是一段能回放、能修改的构造历史。
这件事过去几年没做出来,最大的瓶颈不在模型,在数据。
行业卡了多少年的坎
CAD模型和我们打印用的STL网格,本质上是两个东西。
STL是最终的几何外形。一个零件在屏幕上长什么样,文件里就记录什么样。
但工程师真正在用的CAD文件不是这样。
一个支架在CAD软件里被打开,左边那条参数树里写着:
先在XY平面画一个矩形,长60宽40,往上拉伸8毫米;
然后在顶面画一个圆,直径8毫米,向下挖透;
再选四条竖边,倒2毫米的圆角。
这条参数树就是构造历史。
它记录了设计意图。改尺寸、调参数、把这个支架的孔位从中心挪到边角,靠的全是它。
AI模型如果拿公开的已有的网格数据训练,能生成静态几何,做不了可编辑的源文件。
之前学术界有人尝试过填这个坑。
DeepCAD做了17.8万条序列,Fusion 360 Gallery做了8600条,规模都太小,而且都被锁在最简单的一种操作里:画草图,再拉伸。
倒角、圆角、抽壳、放样、扫掠、布尔运算这些机械设计里最常见的动作,全部不支持。
更近一些的工作叫CAD Recode,去年发的,规模也接近一百万。
但它生成出来的代码长这样,一串坐标的连续调用:机器能执行,人完全改不动。
r = w0.sketch().segment((...),(...)).segment((...),(...))....close().finalize().extrude(8)
对比一下,Zero to CAD生成出来的代码长这样:
plate_length = 60.0
plate_width = 40.0
plate_thickness = 8.0
hole_diameter = 8.0
fillet_radius = 2.0
base = (
cq.Workplane('XY')
.rect(plate_length, plate_width, centered=True)
.extrude(plate_thickness)
)
base = base.edges("|Z").fillet(fillet_radius)
bracket = base.cut(
cq.Workplane('XY').circle(hole_diameter/2).extrude(plate_thickness + 2)
)
result = bracket变量是有名字的,plate_length、hole_diameter、fillet_radius,工程师一看就知道哪个数字是干嘛的。
逻辑顺序也是清楚的,先建底板、倒圆角、再开孔。
想把孔径从8毫米改成10毫米,把hole_diameter那一行改一下就行,整个零件自动重建。
这就是可编辑和不可编辑的区别。
这就是Zero to CAD要解决的问题。
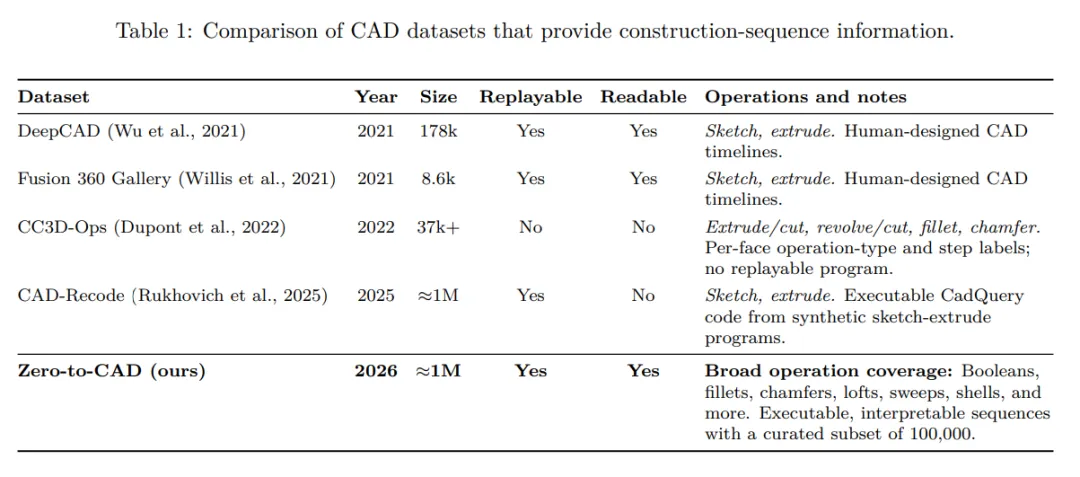
上图是现有CAD数据集对比,加粗那行是Zero to CAD,规模大、可执行、可读、操作覆盖广
Autodesk的解法似乎并不复杂
让一个大模型自己写代码,自己跑,跑不通自己查文档改了再跑。
具体来说,研究团队挑了一个开源大模型gpt-oss-120b,把它扔进一个CAD环境里。
环境给模型配了三件工具,一个执行验证器,一个文档检索器,一个文档正则匹配器。
然后让模型干一件事:
写CadQuery代码(一种用Python语法描述参数化CAD的开源库,可以理解成给程序员用的Fusion 360),执行,看报错,查文档,改代码,再执行,直到几何成立。
论文里举了个很直观的例子。
模型生成了一段沉头孔代码,跑出来报错,说cskHole这个函数缺一个叫cskAngle的参数。
它就自己去查CadQuery文档,找到正确的函数签名,把参数补齐,再跑一次。
一次不行就十次,每个零件最多允许跑100次尝试。
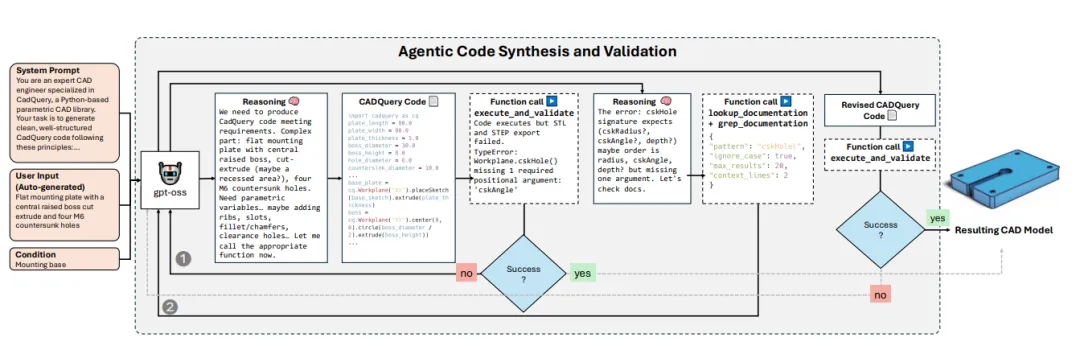
上面是AI代码合成与验证的完整闭环流程图
还有两件事值得提。
一是分两阶段干。
先让模型当零件管理员,按65个常见类别(支架、滑轮、外壳、法兰这些)批量列清单,每批200个,逼它换花样别重复。
然后再按清单去写代码。
二是质量关卡严。
代码能跑只是第一步。还要确认零件不是断成几块的、不是面数少得可疑的方块、能干净地导出STL(用来打印)和STEP(用来CNC)。
这几关都过,才进数据集。
一周时间,一百万个零件
整个流程跑了大概一周。
GPU在2到80块之间动态调度,CPU峰值用到3000核。
处理了602亿输入token,生成了55.9亿输出token。
最终入库999633条。
首次尝试就成功的占22.3%,剩下的平均要试3.3次才过。
更关键的是质量,和ABC(业内最权威的真实CAD数据集)比,Zero to CAD的零件复杂度(平均46.2个面)接近真实数据(50.7),上一代CAD Recode只有16.4,而且一半以上是断成几块的伪零件。
Zero to CAD这一关过滤得很干净。
研究团队再用AI视觉模型测了一遍分布相似度,结论一样:
它合成出来的,比之前的合成数据更像真工程师画的。
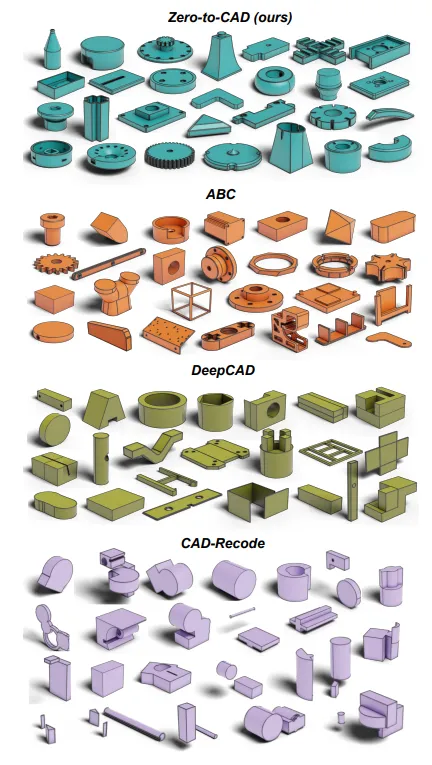
上图是Zero to CAD、ABC、DeepCAD、CAD Recode样本视觉对比
真正出圈的,是后面那个2B的小模型
数据集本身已经是厉害的成果。但这两天火爆的是后面的一个收尾实验。
研究团队拿那一百万条合成数据,全量微调了一个Qwen3-VL-2B-Instruct。这是一个20亿参数的视觉语言模型,能塞进消费级显卡甚至手机里。
任务是图像到代码:给8张多视角渲染图,输出能跑的CadQuery代码,重建几何。
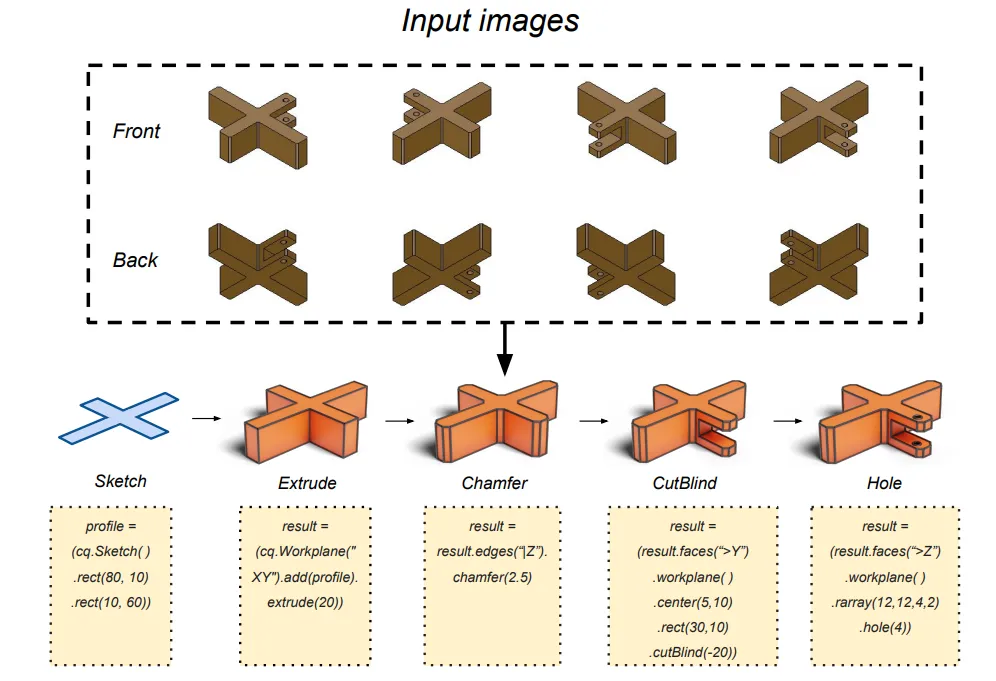
整个零件由草图、拉伸、倒角、挖孔、打孔几个动作组合而成。
测试结果在文章开头说过,自家测试集82.1%的成功率,把GPT-5.2 High(72.2%)按在地上。
而基础Qwen不微调只有6.6%。
研究团队自己也很坦诚地说了一个限制。
把这个模型放到ABC(真实人类设计的CAD)上做泛化测试时,成功率掉到61%,IoU(衡量重建几何和原始几何重合程度的指标,1是完全重合,0是完全不沾边)也下降明显。
GPT-5.2在ABC上的衰减反而更小。
这个对比说明了两件事。
一件是这套合成数据真的能让一个小模型从零学会一项GPT-5.2级别才能勉强做的活。
另一件是合成数据训练出来的模型,迁移到真实数据上还有距离。
社区评论区的反应也分两派。
有人肯定对于一个能跑在手机上的2B模型,这个表现已经相当惊人。
而有些质疑是指那些被算成成功的结果里,到底有多少是2.5D的简单平面拉伸?
多少是真正需要空间感、多平面方向、多个草图相互参考的3D几何?
这个问题论文里没有正面回答。
从前面的图片里能看到的零件类型不少,但要真做工业级的复杂壳体、多孔配合面、带斜度的精铸件,目前的样本分布够不够。

上图是ABC真实数据集上的重建对比(Ground Truth对比微调后的Qwen3 VL 2B对比GPT-5.2
这事和3D打印有什么关系
说回我们的行业。
很多同行最大的痛点之一是设计成本。
一个客户拿着草图来,要你给他做一批支架、夹具、外壳,传统流程是设计师在CAD软件里画,验证完打样。
设计费摊到每件上,比材料费和打印工时加起来还贵。
如果AI能把这个流程压缩到分钟级,整个小批量定制的经济模型就变了。
Zero to CAD指向的就是这条路。
它现在还做不到完美,但已经把基础能力跑通:
给图像,能生成可编辑的CadQuery代码;
这个代码能直接导出STL进切片,也能导出STEP。
模型权重和数据集都开源放在HuggingFace上(ADSKAILab/Zero-To-CAD-Qwen3-VL-2B),消费级显卡能本地跑,不用调API。
对企业用户来说,最直接能做的几件事:
做内部设计提效工具。
把客户发来的参考图丢给模型,先生成一版基础几何,设计师在这版基础上调整,比从零画快很多。
还可以做产品配置工具。
比如做定制夹具的厂家,可以训练一个领域内的小模型,让客户上传工件照片就生成对应的夹具设计。
对个人用户和小工作室来说,更实用的是关注HuggingFace上后续会出现的微调版本。
Autodesk放出了基础模型,社区基本一定会有人在它上面继续微调,比如专门针对某些特定行业应用的版本。
这些垂类微调出来的小模型,可能比通用大模型在具体场景上更好用。
但61%的真实数据成功率,意味着现在还不能无人值守地用。

Autodesk在论文里也很坦诚地放了一组失败案例。
薄壁断开、孔位偏移、几个零件浮在空中没连上、看起来像零件其实加工不出来。
这些失败现在还得靠人眼把关。
把它当一个高效的草稿生成器,比把它当一个全自动设计师,更现实。
写在最后
研究团队说他们没有引入视觉反馈,这也是为什么模型还无法可靠地检测这类几何缺陷。
也就是说,Zero to CAD的整套自我修正机制,是语法层面和几何拓扑层面的修正,不是工程合理性层面的判断。
模型能保证代码能跑、几何可行、能导出,但保证不了这是一个能合理加工出来的零件。
这条路的下一段,大概率要靠两件事补齐。
3D打印这一项尤其值得期待。
因为打印的可制造约束相对清晰,悬垂角、最小壁厚、支撑位置这些规则都有现成的判定逻辑,容易做进自动验证里。
这也意味着,3D打印很可能是AI生成CAD最先跑通商用闭环的工艺。
回到今天这篇论文。
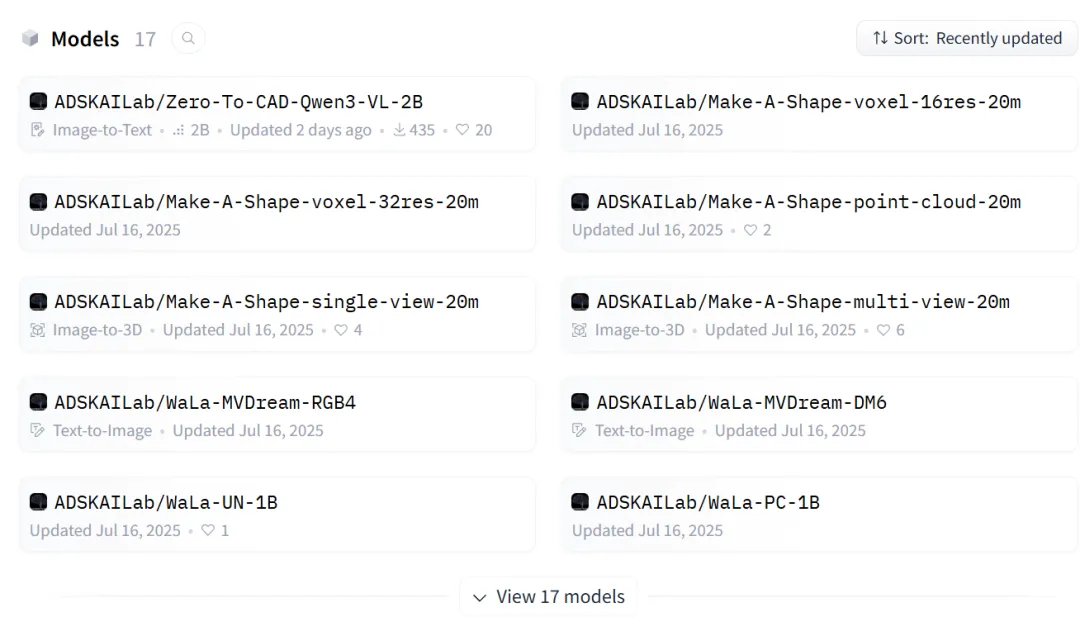
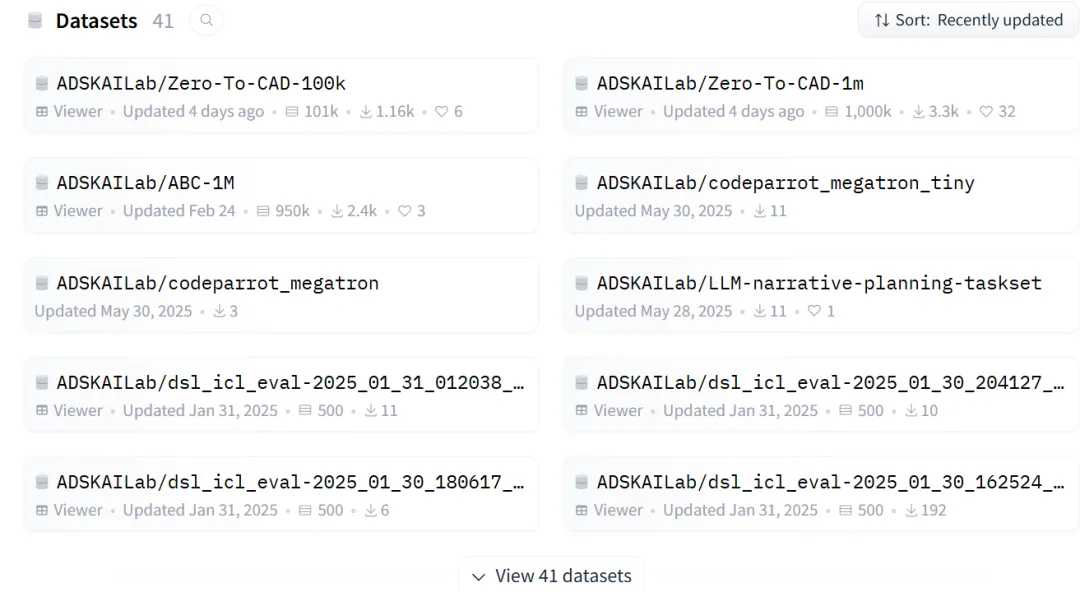
Autodesk这次放出来的还是是一整套可以直接用的资产:
100万条带完整构造历史的CAD数据集、一个微调好的2B模型权重、一份开源的训练代码,全在HuggingFace上。
消费级显卡能本地跑,不用调API。
现在数据和基础模型都开源了,剩下的就看谁动作快。
Autodesk自己当然会把这套能力慢慢嵌进自己的软件栈。
延伸阅读:Claude直连Fusion/Blender,3D建模能力的重新定价
而其他所有做3D打印软件生态的厂家,再加上一批做AI生成3D内容的企业,理论上都在同一个起跑线上。
本文是AM易道对论文的解读和转述,带有大量主观判断、内容取舍和添加行业视角,原文信息密度大、专业细节多,如果您是相关领域的专业读者,强烈建议直接阅读原文,本文的内容可能与原作者的严谨表述存在部分差异。
论文:
资产(HuggingFace):
项目集合页(所有资产汇总):https://huggingface.co/collections/ADSKAILab/zero-to-cad
100万条完整数据集:https://huggingface.co/datasets/ADSKAILab/Zero-To-CAD-1m
10万条精选子集:https://huggingface.co/datasets/ADSKAILab/Zero-To-CAD-100k
2B微调模型:https://huggingface.co/ADSKAILab/Zero-To-CAD-qwen-vl-2B
 点赞
点赞
 反对
反对
 收藏
收藏
 分享
分享


AM易道
读懂3D打印卓越与演变之道
 标签
标签
 近期热门
近期热门











 读懂3D打印卓越与演变之道
读懂3D打印卓越与演变之道